How Vapi AI Works: A Deep Dive into Real-Time Voice Architecture
How Vapi AI Works: Inside a Real-Time Voice AI System
Short description
Voice AI feels natural when it works and painfully obvious when it doesn’t. Behind every smooth conversation is an AI system operating under extreme latency, accuracy, and reliability constraints.
This post explores how a system like Vapi works under the hood—how real-time audio, speech models, large language models, and voice synthesis are composed into a single AI-driven experience.
Why Voice AI Is Fundamentally Different from Chat AI
At first glance, voice AI looks like chat AI with an audio interface. In practice, it is a different class of AI system.
Voice interactions are continuous, not turn-based
Latency is measured in milliseconds, not seconds
Users perceive failures instantly
This forces voice AI systems to prioritize streaming, incremental processing, and graceful degradation over perfect responses.
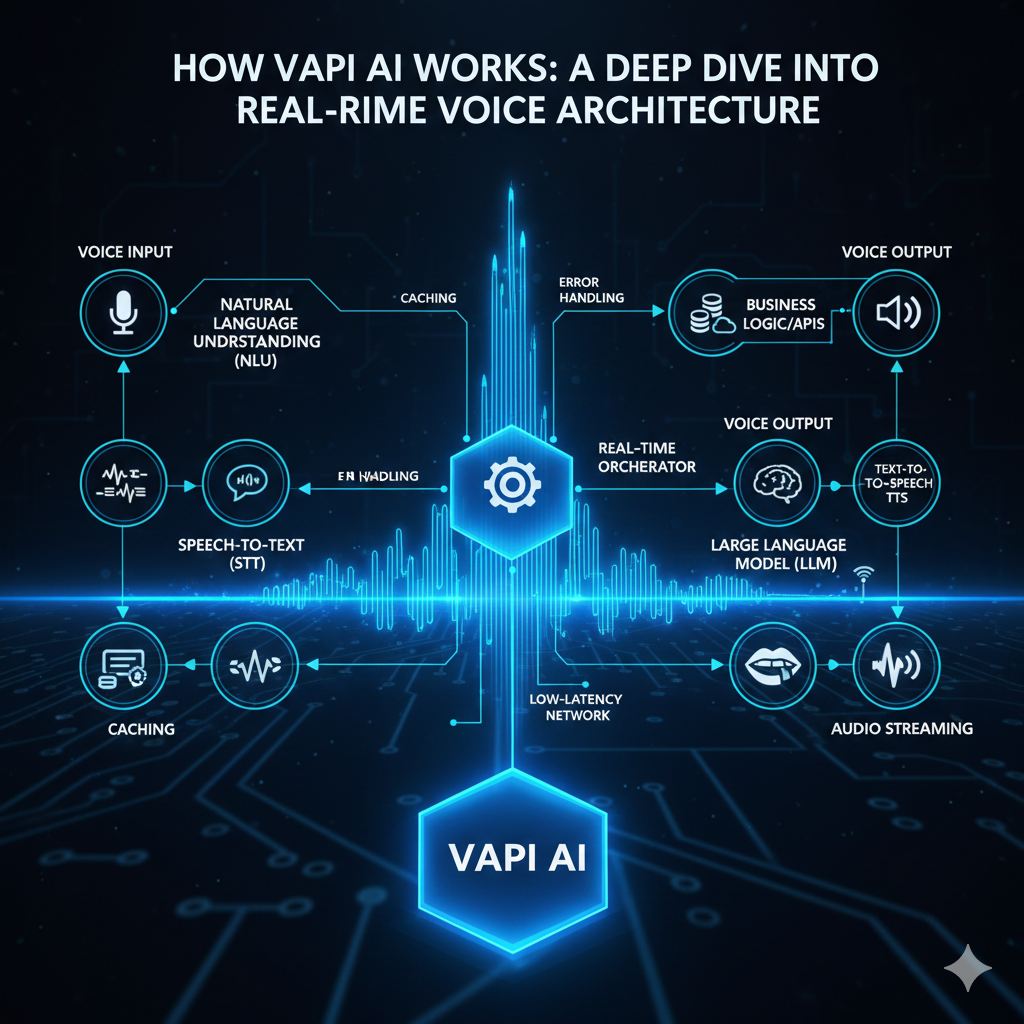
The AI Pipeline at a High Level
Vapi’s architecture can be understood as an AI inference pipeline operating on live audio.
Audio is captured and streamed in real time
Speech is transcribed incrementally
An LLM generates a contextual response
Text is synthesized into speech
Audio is streamed back to the user
Each stage is powered by a different class of AI model, optimized for a specific task.
Audio as Model Input, Not a File
In voice AI, audio is not an upload—it is a live signal.
Vapi processes audio as a continuous stream of small frames, allowing downstream models to begin inference immediately.
Lower end-to-end latency
Support for interruptions and barge-ins
More natural conversational flow
This framing of audio as a stream rather than data fundamentally shapes the entire system.
Speech-to-Text: Streaming Inference
Speech recognition in Vapi is designed for real-time inference, not post-processing accuracy.
The transcription model produces:
Partial transcripts for early reasoning
Final transcripts for accuracy
These partial results allow the system to predict intent before the user finishes speaking, reducing response delay.
LLM Reasoning Under Latency Constraints
The LLM is responsible for reasoning, intent resolution, and response generation.
In voice AI, LLM usage is tightly constrained:
Context must be minimal and relevant
Responses must be concise
Inference time must be predictable
Unlike chatbots, the LLM is not the center of the system—it is one stage in a real-time pipeline.
Text-to-Speech: Where AI Becomes Perceptible
Text-to-speech is the most human-facing component of the system.
Vapi generates speech incrementally, converting partial text into audio without waiting for the full response.
Faster perceived responses
More natural pacing
Reduced conversational gaps
Any delay or unnatural prosody here is immediately noticeable.
Conversation State and Context Management
Voice conversations are stateful and time-sensitive.
The system must track:
Conversation history
User intent and corrections
Interruption boundaries
This state is continuously updated and selectively passed to the LLM to balance relevance with latency.
Event-Driven Coordination Between AI Models
Rather than a linear flow, Vapi operates as an event-driven AI system.
Audio frame received
Transcript updated
Intent detected
Speech generated
This allows components to operate independently while remaining loosely coupled.
Why Modularity Matters in AI Systems
Each AI capability in Vapi is intentionally isolated.
Speech models can be swapped independently
LLMs can evolve without breaking audio logic
Latency can be tuned per stage
This modularity allows rapid experimentation while preserving system stability.
Trade-Offs the System Explicitly Makes
Vapi’s architecture optimizes for specific outcomes:
Responsiveness over perfect accuracy
Streaming inference over batch processing
Resilience over simplicity
These trade-offs are what make voice interactions feel natural rather than robotic.
Closing Thought
Voice AI is not just about better models—it is about how models are composed into systems.
Vapi demonstrates that the real challenge lies in orchestrating AI components under real-world constraints, where milliseconds and user perception matter more than theoretical accuracy.