When RabbitMQ Notifications Go Wrong: The Production Failures No One Warns You About
Why Your RabbitMQ Notification System Works in Dev but Fails in Production
Short description:
Sending notifications with RabbitMQ looks simple — publish a message, consume it, send email or push. But under real traffic, retry storms, duplicate sends, ordering issues, and dead-letter queues start appearing. This post breaks down what actually goes wrong and how production systems handle it.
The Illusion of Simplicity
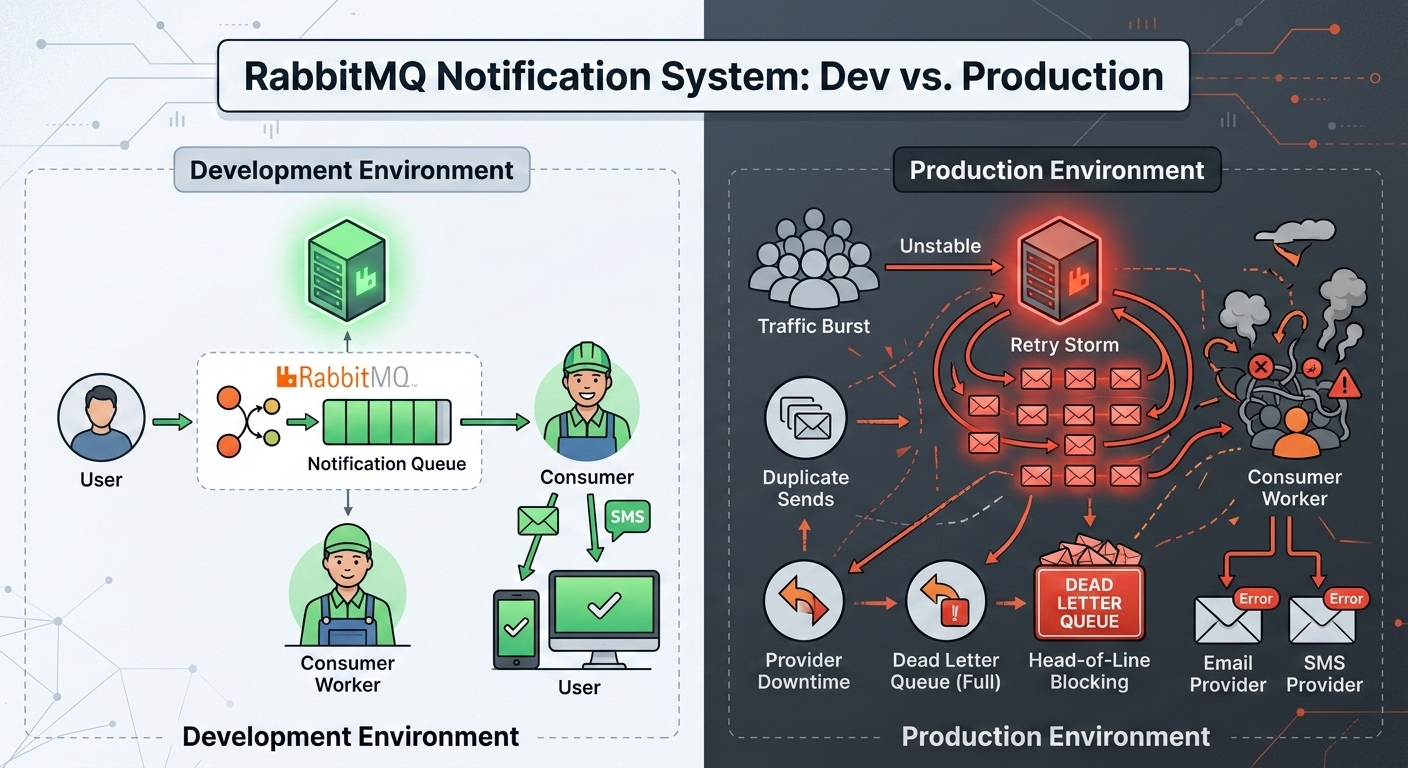
A typical notification architecture looks clean:
User performs an action
Backend publishes a message to RabbitMQ
A worker consumes the message
Email/SMS/Push is sent
It works beautifully in development.
Low traffic. No failures. Instant processing.
Then production happens.
What Changes in Production?
Three things change immediately:
Traffic becomes bursty
Downstream providers fail unpredictably
Retries multiply load
RabbitMQ doesn’t fail you. Your assumptions do.
Problem #1: Notifications Are Not Idempotent by Default
If a consumer crashes after sending an email but before acknowledging the message, RabbitMQ will re-deliver it.
From the broker’s perspective, the message was never processed.
From the user’s perspective?
“Why did I get this email twice?”
This is not a RabbitMQ issue. It’s a system design issue.
Production Fix
Introduce idempotency at the notification layer:
Store a unique notification ID in the database
Mark as “sent” before ACK
Check existence before sending again
Exactly-once delivery doesn’t exist. Idempotency does.
Problem #2: Retry Storms
Let’s say your email provider is temporarily down.
All consumers start failing. Messages are re-queued instantly.
Consumers pick them up again immediately.
This creates a retry loop that amplifies load.
Now you’re not just failing — you’re DDoS-ing your own system.
Production Fix
Use delayed retries with Dead Letter Exchanges (DLX):
Primary queue → if failed → dead-letter queue
Dead-letter queue with TTL → message re-routed after delay
This creates controlled backoff instead of chaos.
Problem #3: One Queue for All Notification Types
Many teams push email, SMS, push, and webhook notifications into one queue.
This causes head-of-line blocking.
If SMS provider slows down, email notifications wait behind it.
Different notification types have different latency and reliability characteristics.
Production Fix
Separate queues by channel:
email.notifications
sms.notifications
push.notifications
This isolates failure domains.
Problem #4: Ordering Assumptions
RabbitMQ preserves order within a single queue — until you scale consumers.
With multiple consumers:
Processing order becomes non-deterministic
Retries break sequencing
If your system assumes “Welcome email must come before Promotion email,” you have a hidden bug.
Production Fix
Avoid strict ordering requirements when possible
Use per-user routing keys if ordering is critical
Design notifications to be independent
Problem #5: No Backpressure Strategy
During a marketing campaign, traffic spikes 20x.
If consumers can’t keep up, queue length grows indefinitely.
Eventually:
Memory pressure increases
Disk I/O spikes
Latency explodes
Production Fix
Set queue length limits
Apply publisher confirms
Throttle producers when necessary
Backpressure is not optional at scale.
Problem #6: Ignoring Dead Letter Queues
Dead-letter queues are often configured and then forgotten.
But DLQs are not trash bins.
They are signals.
If messages land in DLQ:
Schema may have changed
Consumer logic may be broken
Provider may be rejecting specific content
DLQ growth without monitoring is silent data loss.
The Architecture Mature Teams Use
Production-grade notification systems often include:
Channel-specific queues
Retry queues with exponential backoff
DLQ monitoring and alerting
Idempotency keys
Rate limiting per provider
RabbitMQ is just the transport. Reliability comes from design.
What Makes Notifications Special?
Notifications are user-facing.
Unlike analytics pipelines, mistakes are visible.
Duplicate sends reduce trust
Delayed messages reduce relevance
Missing notifications break user flows
This makes reliability and correctness more important than raw throughput.
Final Thought
RabbitMQ does exactly what it promises: reliable message delivery.
But reliability at the broker level does not guarantee correctness at the system level.
Notification systems fail not because RabbitMQ is flawed — but because retries, ordering, idempotency, and backpressure are underestimated.
Once you design for failure instead of assuming success, RabbitMQ becomes a powerful backbone for user-facing communication.